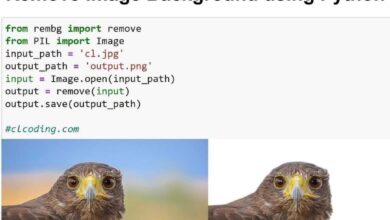
Extract Text from PDF with Python
For this tutorial, I’ll be using Python 3.6.3. You can use any version you like (as long as it supports the relevant libraries).
You will require the following Python libraries in order to follow this tutorial:
- PyPDF2 (to convert simple, text-based PDF files into text readable by Python)
- textract (to convert non-trivial, scanned PDF files into text readable by Python)
- NLTK (to clean and convert phrases into keywords)
Each of these libraries can be installed with the following commands inside terminal (on macOS):
pip install PyPDF2pip install textractpip install nltk
This will download the libraries you require to parse PDF documents and extract keywords. In order to do this, make sure your PDF file is stored within the folder where you’re writing your script.
Start up your favorite editor and type:
Note: All lines starting with # are comments.
Step 1: Import all libraries
import PyPDF2 import textractfrom nltk.tokenize import word_tokenizefrom nltk.corpus import stopwords
Step 2: Read PDF file
#Write a for-loop to open many files (leave a comment if you'd like to learn how).
filename = 'enter the name of the file here'
#open allows you to read the file.
pdfFileObj = open(filename,'rb')
#The pdfReader variable is a readable object that will be parsed.
pdfReader=PyPDF2.PdfFileReader(pdfFileObj)
#Discerning the number of pages will allow us to parse through all the pages.
num_pages = pdfReader.numPages
count = 0
text = ""
#The while loop will read each page.
while count < num_pages:
pageObj = pdfReader.getPage(count)
count +=1
text += pageObj.extractText()
#This if statement exists to check if the above library returned words. It's done because PyPDF2 cannot read scanned files.if text != "":
text = text
#If the above returns as False, we run the OCR library textract to #convert scanned/image based PDF files into text.
else:
text = textract.process(fileurl, method='tesseract', language='eng')
#Now we have a text variable that contains all the text derived from our PDF file. Type print(text) to see what it contains. It likely contains a lot of spaces, possibly junk such as '\n,' etc.
#Now, we will clean our text variable and return it as a list of keywords.
Step 3: Convert text into keywords
#The word_tokenize() function will break our text phrases into individual words.
tokens = word_tokenize(text)
#We'll create a new list that contains punctuation we wish to clean.
punctuations = ['(',')',';',':','[',']',',']
#We initialize the stopwords variable, which is a list of words like "The," "I," "and," etc. that don't hold much value as keywords.
stop_words = stopwords.words('english')
#We create a list comprehension that only returns a list of words that are NOT IN stop_words and NOT IN punctuations.
keywords = [word for word in tokens if not word in stop_words and not word in punctuations]
Now you have keywords for your file stored as a list. You can do whatever you want with it. Store it in a spreadsheet if you want to make the PDF searchable or parse a lot of files and conduct a cluster analysis. You can also use it to create a recommender system for resumes for jobs.
I hope you found this tutorial valuable! If you have any requests, would like some clarification, or find a bug, please let me know!